Blog
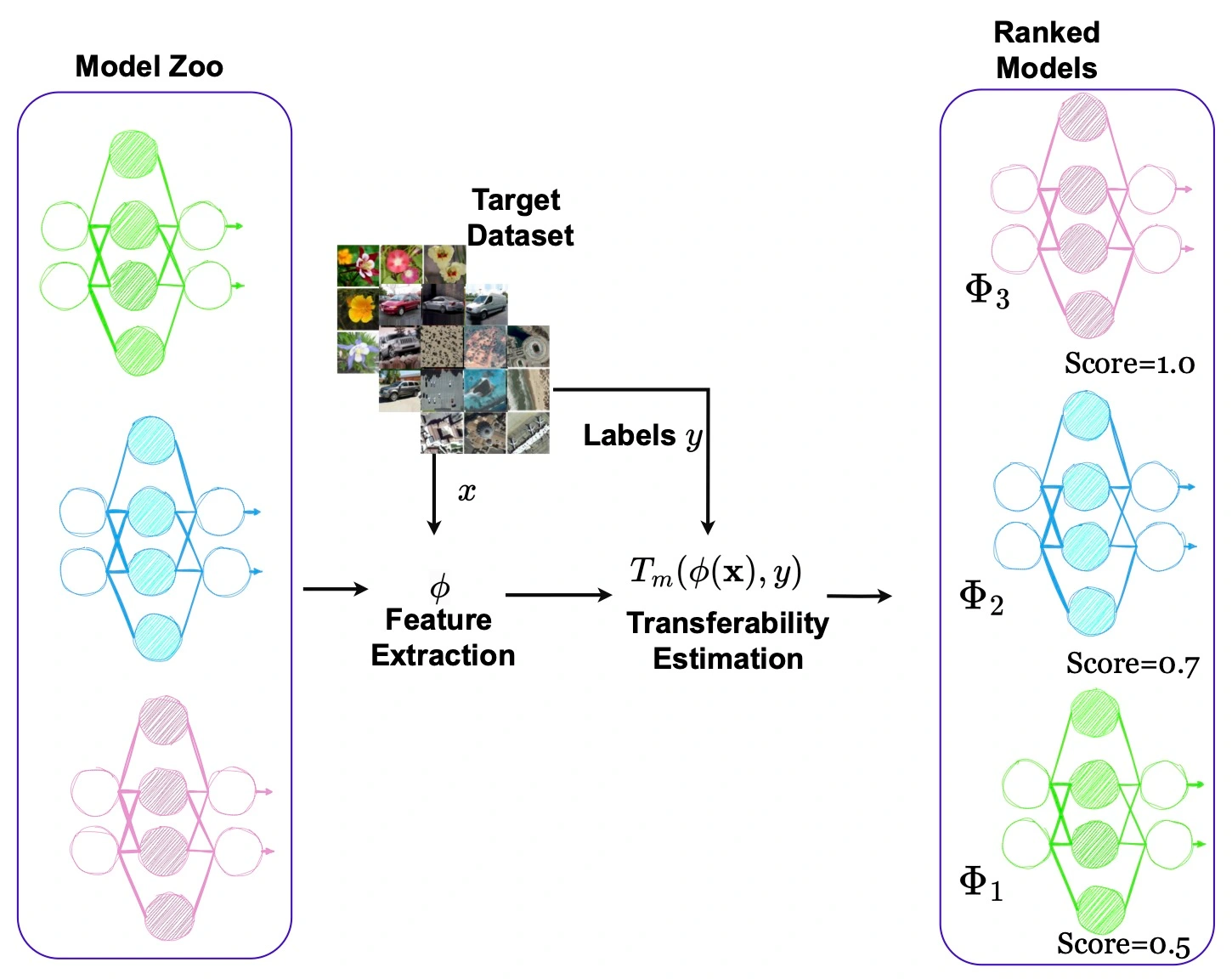
Benchmarking Source Independent Transferability Estimation.
Discover why the next AI efficiency frontier isn't just smaller models - it's smarter tokens.

We explain how to get near full fine-tuning performance with a fraction of the cost, a small set of parameters, and less memory, with LoRA. Read before your next fine-tuning job.

We present SERENA, a neuro-inspired solution for continual learning that mimics the self-regulated neurogenesis process in the human brain.

We show how sparse training helps us learn much faster while forgetting less. Based on our CPAL paper "Continual Learning with Dynamic Sparse Training".
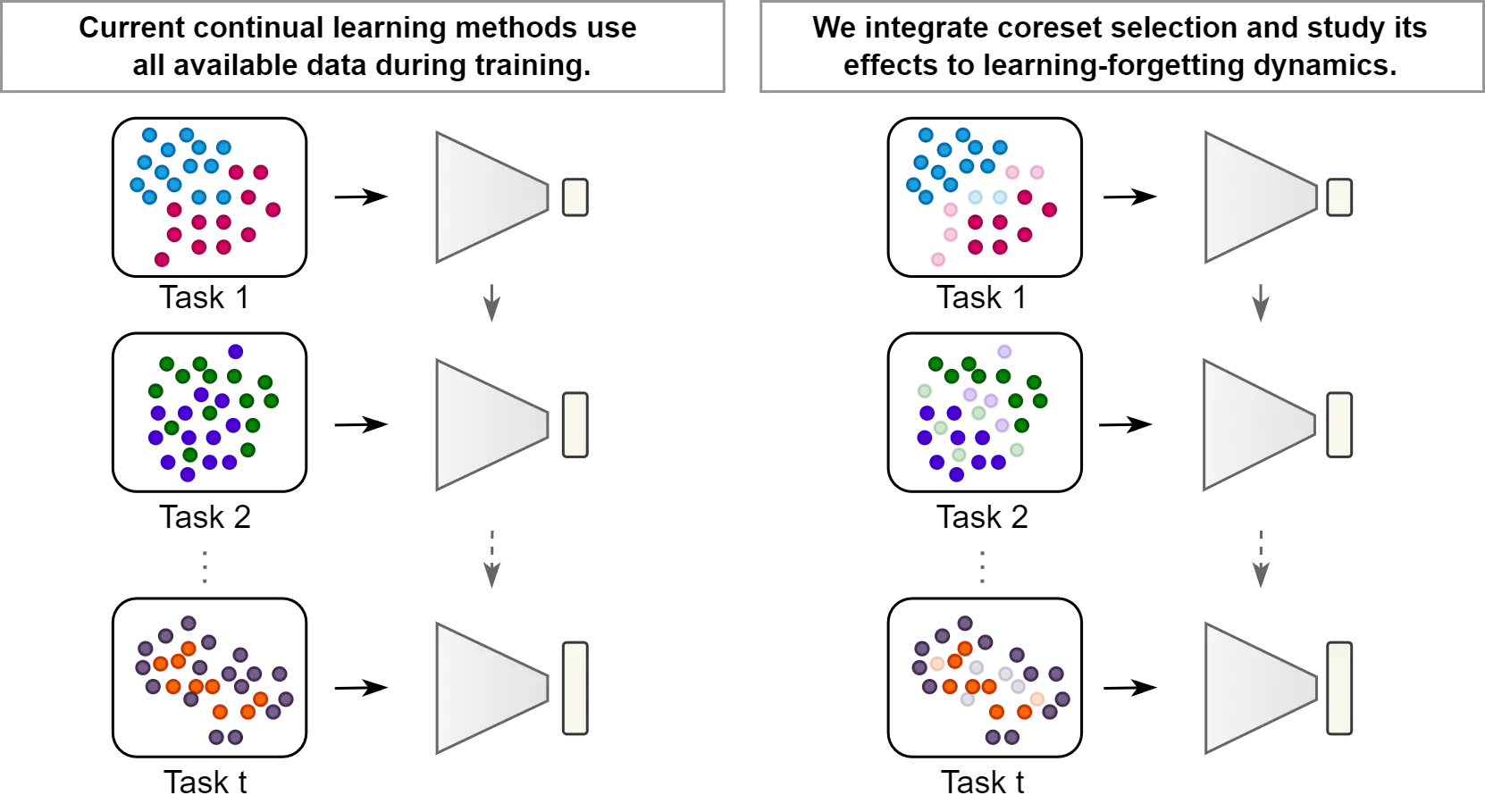
We show how continual learning benefits from selecting only the more informative (or surprising) new data points.".
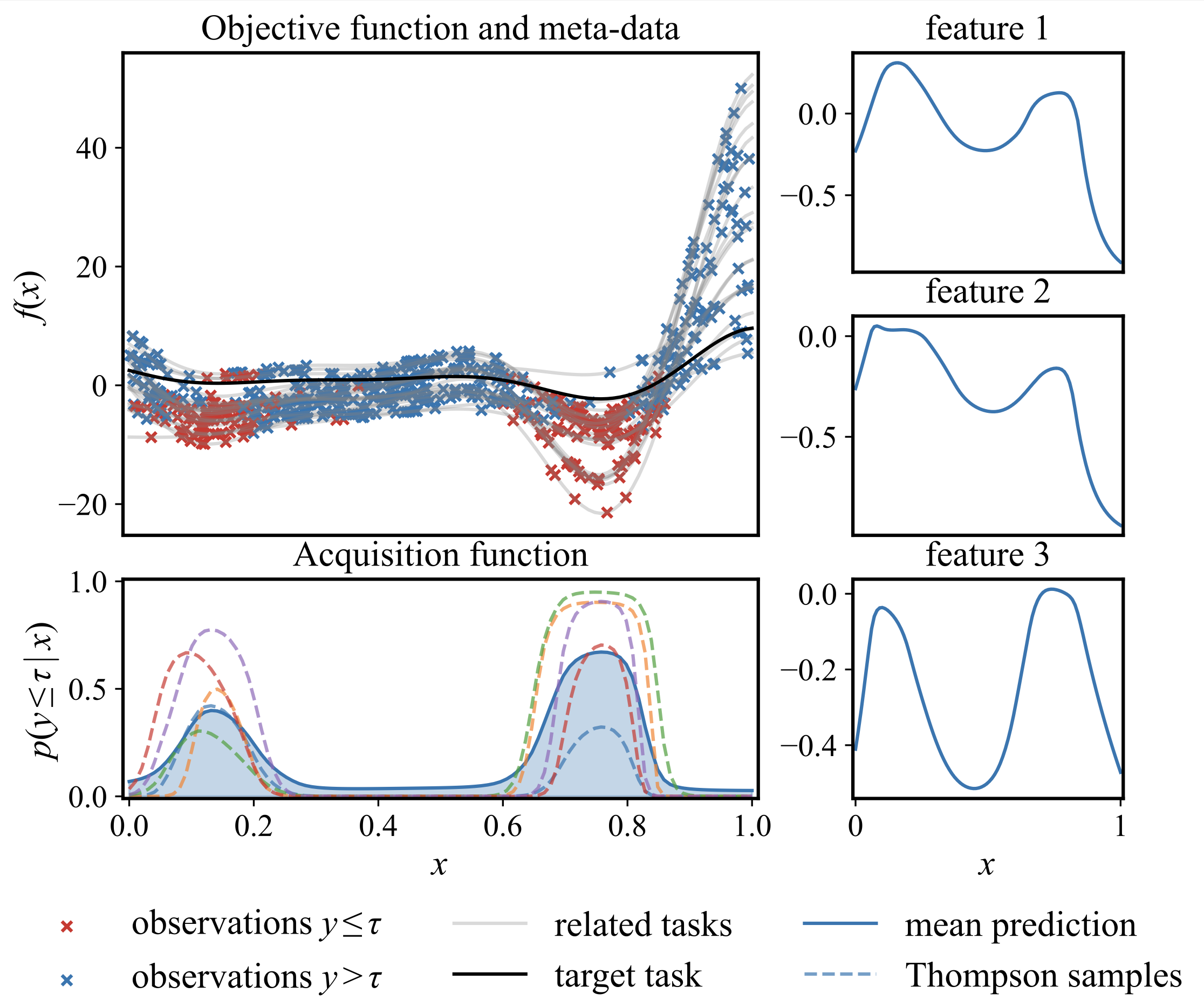
We introduce MALIBO, a novel and scalable framework that leverages meta-learning for fast and efficient Bayesian optimization.
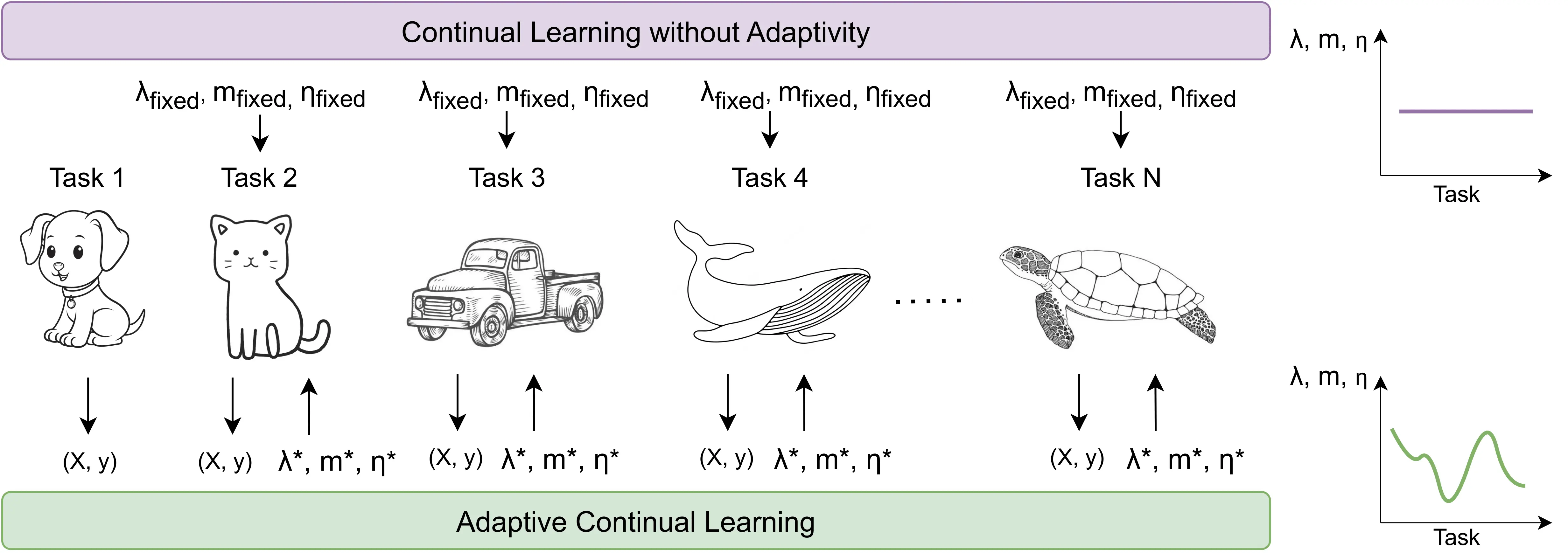
We introduce AdaCL, a new method that optimally adapts continual learning hyperparameters to every new task.

About why we wrote our paper

We visited Probabl in Paris to discuss open source and open science.
How NOT to benchmark your transferability estimation metric
Benchmarking Source Independent Transferability Estimation.
A Shift Toward Data-Centric Compression
Discover why the next AI efficiency frontier isn't just smaller models - it's smarter tokens.
LoRA and Beyond. Fine-Tuning LLMs for Anyone, Anywhere
We explain how to get near full fine-tuning performance with a fraction of the cost, a small set of parameters, and less memory, with LoRA. Read before your next fine-tuning job.
Self-Regulated Neurogenesis for Online Data-Incremental Learning
We present SERENA, a neuro-inspired solution for continual learning that mimics the self-regulated neurogenesis process in the human brain.
Continual Learning with Dynamic Sparse Training
We show how sparse training helps us learn much faster while forgetting less. Based on our CPAL paper "Continual Learning with Dynamic Sparse Training".
Continual Learning with Informative Samples
We show how continual learning benefits from selecting only the more informative (or surprising) new data points.".
Meta-learning for Likelihood-free Bayesian Optimization
We introduce MALIBO, a novel and scalable framework that leverages meta-learning for fast and efficient Bayesian optimization.
Adaptive Continual Learning
We introduce AdaCL, a new method that optimally adapts continual learning hyperparameters to every new task.
The AutoML Benchmark
About why we wrote our paper
OpenML x Probabl Hackathon
We visited Probabl in Paris to discuss open source and open science.
Analysis
Discover why the next AI efficiency frontier isn't just smaller models - it's smarter tokens.
We explain how to get near full fine-tuning performance with a fraction of the cost, a small set of parameters, and less memory, with LoRA. Read before your next fine-tuning job.
We show how sparse training helps us learn much faster while forgetting less. Based on our CPAL paper "Continual Learning with Dynamic Sparse Training".
We show how continual learning benefits from selecting only the more informative (or surprising) new data points.".
Benchmarking
Benchmarking Source Independent Transferability Estimation.
About why we wrote our paper
Hackathon
We visited Probabl in Paris to discuss open source and open science.
Method
We present SERENA, a neuro-inspired solution for continual learning that mimics the self-regulated neurogenesis process in the human brain.
We introduce MALIBO, a novel and scalable framework that leverages meta-learning for fast and efficient Bayesian optimization.
We introduce AdaCL, a new method that optimally adapts continual learning hyperparameters to every new task.
Analysis
A Shift Toward Data-Centric Compression
Discover why the next AI efficiency frontier isn't just smaller models - it's smarter tokens.
LoRA and Beyond. Fine-Tuning LLMs for Anyone, Anywhere
We explain how to get near full fine-tuning performance with a fraction of the cost, a small set of parameters, and less memory, with LoRA. Read before your next fine-tuning job.
Continual Learning with Dynamic Sparse Training
We show how sparse training helps us learn much faster while forgetting less. Based on our CPAL paper "Continual Learning with Dynamic Sparse Training".
Continual Learning with Informative Samples
We show how continual learning benefits from selecting only the more informative (or surprising) new data points.".
Benchmarking
How NOT to benchmark your transferability estimation metric
Benchmarking Source Independent Transferability Estimation.
The AutoML Benchmark
About why we wrote our paper
Hackathon
Method
Self-Regulated Neurogenesis for Online Data-Incremental Learning
We present SERENA, a neuro-inspired solution for continual learning that mimics the self-regulated neurogenesis process in the human brain.
Meta-learning for Likelihood-free Bayesian Optimization
We introduce MALIBO, a novel and scalable framework that leverages meta-learning for fast and efficient Bayesian optimization.
Adaptive Continual Learning
We introduce AdaCL, a new method that optimally adapts continual learning hyperparameters to every new task.