Continual Learning with Dynamic Sparse Training
Continual Learning with Dynamic Sparse Training: Exploring Algorithms for Effective Model Updates
Murat Onur Yildirim, Elif Ceren Gok Yildirim, Ghada Sokar, Decebal Constantin Mocanu, Joaquin Vanschoren.
TL;DR: This blog post dives into our recent paper “Continual Learning with Dynamic Sparse Training: Exploring Algorithms for Effective Model Updates” (📄 Paper, 🤖 Code) published in CPAL 2024. We explore how Continual Learning can benefit from Dynamic Sparse Training, a process that closely mirrors the brain’s ability to constantly rewire and optimize its connections. Read on for a brief overview of our key findings 😊
Hey there!
Have you ever wondered how our brains learn new skills without forgetting the old ones? Imagine learning a new language while still chatting away in your native tongue, or watching yourself grow from crawling to walking, running, and even biking—all while never losing that ability to crawl! It’s truly fascinating, and yet, teaching our deep learning models to do the same remains an exciting challenge.
The Challenge: Catastrophic Forgetting
Traditional neural networks tend to overwrite older information when learning new tasks, which isn’t very brain-like at all. This major hurdle is called catastrophic forgetting. Imagine if every time you learned a new recipe, you suddenly couldn’t remember your grandma’s secret and delicious recipe anymore! That’s where continual learning (CL) steps in—allowing models to learn from a stream of data without letting past knowledge vanish into thin air.

Neuroscience: Nature’s Blueprint
In neuroscience, it’s well known that our brain is always under a change and on the move! Our synaptic connections are constantly being reshaped or kept steady based on what we experience—a delightful dance of plasticity and stability that fuels our lifelong ability to learn and adapt. Picture your brain as a vibrant, ever-changing city where new pathways light up and old ones evolve based on your experiences.
A Smart Way to Build a Brain
To mimic this amazing ability, a technique called Dynamic Sparse Training (DST) offers an artificial version of the plasticity and the stability, ensuring that our neural networks remain both efficient and adaptable over time. Imagine starting with an overparameterized network, like a bustling metropolis with way more roads than you actually need. But instead of keeping all these roads open, DST acts as an ingenious city planner: it decides which roads to close down (prune) and which new ones to build (regrow) so that traffic flows optimally—all while staying within a fixed budget.
Step 1: The Beginning with Initialization
We kick things off by initializing our network using one of two methods: - Uniform Initialization: Every layer gets an equal share of connections, kind of like giving every neighborhood the same number of streets. - Erdős-Rényi Kernel (ERK) Initialization: Instead of treating all layers equally, ERK smartly allocates more connections to the “busy” areas (the layers with more parameters) and fewer to the “quiet” ones. This is a bit like investing more in the main highways that keep the city moving.
Step 2: Training, Pruning, and Regrowing
After some initial training, the network doesn’t just sit idle but actively refines itself. Here’s how it works: - Pruning: Based on the magnitude of the weights, the network prunes away a fixed number (which can be scheduled) of the least important connections. Think of it as cutting off the rarely used, winding side streets to save resources. - Regrowth: To maintain the same overall sparsity level for each task, the network then regrows exactly same amount of connections. And guess what? There are three main approaches to choose which connections to regrow: - Random: Sometimes, a bit of randomness helps explore new possibilities, like testing out an unexpected shortcut. - Unfired: Alternatively, the model can explore the connections that is never tried or checked before. - Gradient-based: Finally, it can look at the gradient or momentum signals that indicate which potential connections could boost performance—and regrow those most promising ones.
Step 3: Sharing is Caring
What’s truly fascinating in this approach is that, even though the network is carving out different “subnetworks” for each new task, it also allows for sharing connections between tasks. This means that if two tasks are similar, they can use the same neural “road,” which enhances knowledge sharing and makes learning even more efficient. It’s like having a communal library where everyone benefits from the same resources!

Continual Learning: The Ultimate Test
Now, combine DST with Continual Learning (CL)—a setup where a single network learns a series of tasks over time without forgetting earlier ones, just like how you can learn to cook a new recipes without forgetting grandma’s special.
Traditionally, many systems tackle each new task with a separate network or by keeping extra data around. But here, DST is applied to one overparameterized network that evolves over time. As new tasks come along, the network dynamically adjusts itself by pruning away unused connections and regrowing new ones, while allowing to share common connections to build on past knowledge.
A Technical Snapshot
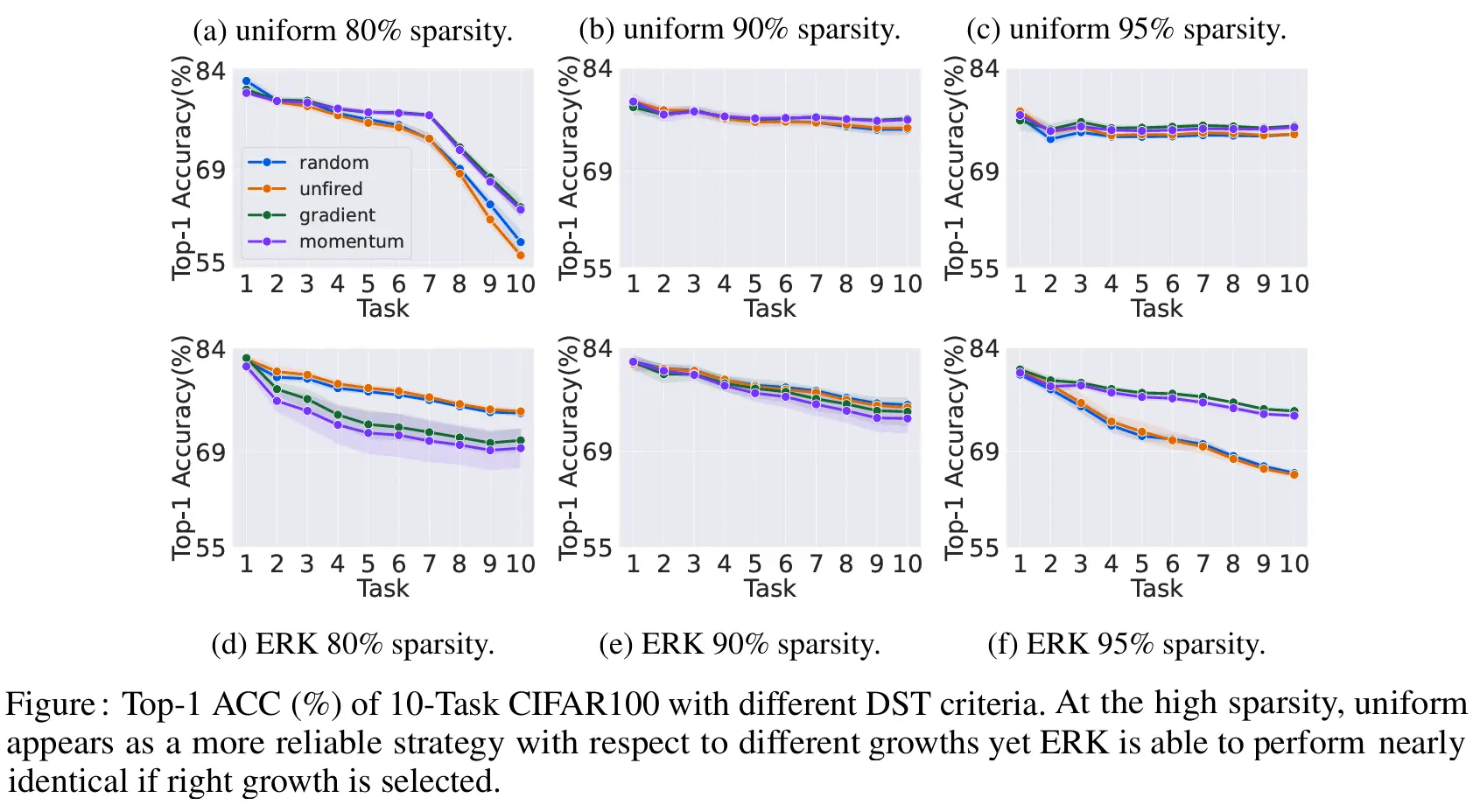
For those of you who love the technical nitty-gritty, here’s a quick summary of the key findings from our study: - Initialization Matters: At low to moderate sparsity levels (around 80–90%), the ERK initialization leverages the network’s capacity more efficiently by assigning fewer connections to narrow layers. This helps in learning incremental tasks effectively. At higher sparsities, ERK still doing its job when the right growth strategy is selected. - Growth Strategy Dynamics: The choice of growth strategy is closely tied to the initialization and the degree of sparsity. While gradient-based and momentum-based growth methods excel at high sparsity by carefully selecting promising connections, random growth performs competitively at lower sparsity levels where there’s less room for exploration. - Adaptive Approaches are Promising: There’s no one-size-fits-all DST setup. Even a simple adaptive strategy that switches between growth methods (like using random growth initially and shifting to gradient-based growth later) can boost performance compared to sticking with a fixed strategy. - Shared Connections Enhance Knowledge Transfer: Allowing the network to share connections between tasks not only saves resources but also boosts overall learning by transferring knowledge from previous tasks, much like how our brains reuse familiar circuits when learning something new.
Bringing All Together and Wrapping It Up
By starting with a clever initialization, then iteratively pruning and regrowing a fixed number of connections based on weight magnitude and gradient signals, DST transforms a single, overparameterized network into a versatile, continually learning powerhouse. And the cherry on top? Allowing subnetworks to share connections across different tasks means that the network not only learns continuously but also builds upon past knowledge, much like our own brains do.
In this study, we dive deep into the various ways to run DST in a continual learning setup, offering both technical insights and inspiration for future research. We believe it is a beautiful blend of neuroscience and engineering—a step closer to creating AI that learns and adapts just like we do. Again, if you want to know more, you can check the paper 😊
Stay curious, keep exploring, and let’s continue pushing the boundaries of what intelligent systems can achieve! 🧠🚀
This post was written by Murat Onur Yildirim and need not reflect the view of co-authors.