A Shift Toward Data-Centric Compression
Introduction
For a long time, ‘Efficient AI’ mostly meant smaller models. We quantized weights, pruned layers, distilled teachers into student models, and celebrated whenever parameter counts went down without performance collapsing. That framing made sense when model size was the primary cost. But that assumption is quietly breaking.
Today’s bottleneck is no longer just how big a model is, but how much data it has to process - long text contexts, high-resolution images, hours of audio and video. Even when the model itself is frozen, inference efficiency degrades because attention scales with sequence length, rather than parameter count. This necessitates a shift in optimization strategy: efficiency is no longer just a model-centric problem, but also a data-centric one. The question shifts from ‘How do we shrink the network?’ to ‘How do we reduce what the network has to look at?’
In modern architectures, ‘data’ appears as tokens. Whether they come from words, image patches, video frames, or audio segments, tokens are the units over which computation scales. Compressing data therefore means compressing tokens. Seen through this lens, a wide range of recent methods across modalities can be understood as forms of token compression. Despite their surface differences, most of them revolve around three core questions:
- Which tokens matter?
- Which tokens are redundant?
- When is it safe to forget?
Different papers answer these questions in quite different ways. As illustrated in Figure 1, these diverse approaches can be categorized into a structured taxonomy based on their underlying mechanisms - such as attention, similarity, query or transformation-based compression - and the specific modalities they target.

Attention-based Methods

Attention-based methods are the most intuitive starting point. The underlying assumption is simple: if a model assigns a low attention score to a token, that token is likely unimportant. Removing it reduces the sequence length and, in turn, the total computation. As illustrated in Fig. 2, Top-K token pruning [1] computes an attention score for each input token, typically relative to the [CLS] token. It then retains only the K highest-scoring tokens for the subsequent layers.
While this works reasonably well in shallow or unimodal settings, it tends to break down in deeper or multimodal models. Attention is inherently layer-dependent. A token that appears unimportant early on may become critical later, particularly once cross-modal interactions or higher-level semantics emerge. As a result, pruning decisions made too early can permanently discard information that the model has not yet learned to exploit.
Several recent analyses highlight this failure mode: pruning based on a single layer often introduces errors that only surface downstream. Balanced Token Pruning [4] makes this trade-off explicit by separating the effect of pruning on the current layer from its impact on future layers. They show that attention-based pruning lacks a single-layer criterion that is optimal across the model’s depth. As a result, attention alone is not a stable importance signal.
To counter this instability, multi-stage approaches extend this idea by delaying decisions. In methods like MustDrop [5], tokens are evaluated during vision encoding, again during prefilling when text semantics appear, and once more during decoding. Only tokens that are consistently deemed irrelevant across stages are removed.
Similarity-based Methods
Across modalities, tokens are often redundant by construction. Adjacent audio frames may often encode the same phonetic content. Neighboring image patches may frequently describe the same surface. Consecutive video frames can be nearly identical. In such cases, the question is if all these tokens are actually needed.
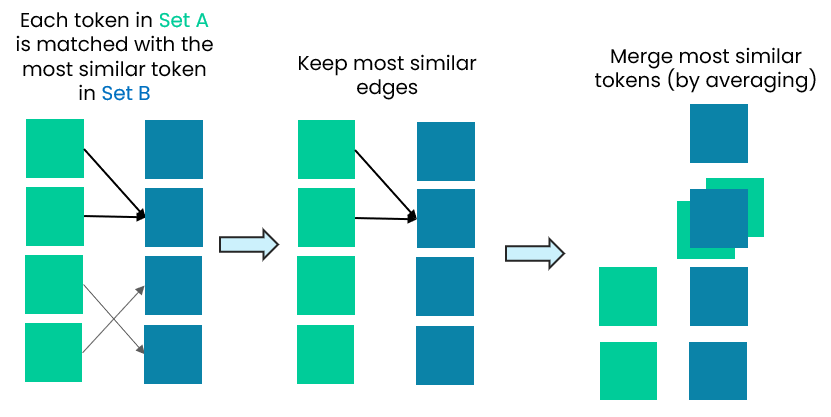
Similarity-based methods exploit this redundancy directly. Rather than deleting tokens outright, they merge those that encode similar information. As illustrated in Fig. 3, this typically involves identifying pairs or groups of tokens with high representational overlap - often measured using metrics such as cosine similarity - and collapsing them into a single shared token. In speech, Adjacent Token Merging [6] combines neighboring frames, preserving the temporal order while reducing the sequence length. In vision-language models, prune-and-merge hybrid methods [7, 8] first keep a small set of salient tokens, then merge nearby or related tokens into them.
As a result, similarity-based approaches tend to be more conservative and robust. They avoid relying on potentially unstable importance estimates and instead operate under the assumption that redundancy is inherent in the input representation and can be removed with limited risk to downstream performance.
Query-based Methods

In multimodal models, a large fraction of tokens may never be relevant to the user’s question. A detailed background patch in an image might be useless for one query and critical for another. As illustrated in Fig 4, models like BLIP-2 [9] address this by introducing a small set of learnable query tokens that perform cross-attention over a frozen encoder. These queries selectively extract only the most relevant visual or audio tokens and pass them to a frozen language model.
This approach is effective because compression is guided directly by task semantics rather than generic importance heuristics. This also explains why query-guided pruning often works better in multimodal reasoning than purely attention-based heuristics. However, this benefit comes with trade-offs. Query-based compression is inherently context-dependent: the same input may yield different compressed representations under different prompts, which can complicate reuse, caching, and systematic evaluation.
Transformation-based Methods

Some approaches avoid token selection entirely by changing how inputs are represented. Instead of generating a large number of fine-grained tokens and compressing them later, transformation-based methods produce a smaller token set from the start. Pooling [10], pixel unshuffling [11, 12] and spatial convolutions [13] are some of the approaches that fall into this category. As illustrated in Fig. 5, this compression happens implicitly through the representation itself, by mapping dense input regions to a coarser token grid.
For example, in LLaMA-VID [14], rather than encoding each frame into hundreds of patch tokens, every frame is represented using just two tokens: one capturing instruction-guided context (generated via cross-modal attention between the user query and image features) and one capturing general visual content (generated via average pooling over the image features). This kind of compression scales well and avoids the complexity of dynamic pruning logic.
Conclusion
Seen together, these families of methods suggest a broader shift in how we think about efficiency. Token compression is not merely a trick to make models faster; it is an implicit statement about what information is worth representing at all. Tokens carry structure, order, and semantics that interact across layers and modalities. Much of the current research can be reinterpreted as a search for the answer to a single unresolved question: when does the model know enough to safely compress? Looking ahead, the most promising directions likely lie in hybrid and adaptive schemes that treat compression as a progressive process rather than a one-shot decision. As inputs continue to grow and model sizes begin to plateau, data-centric compression moves from an implementation detail to a design choice. Efficiency is therefore shaped not just by model size, but by the mechanisms that regulate which information is retained across layers.
References
[1] Xu, Xuwei, Changlin Li, Yudong Chen, Xiaojun Chang, Jiajun Liu, and Sen Wang. 2023. “No Token Left Behind: Efficient Vision Transformer via Dynamic Token Idling.” arXiv preprint arXiv:2310.05654. https://arxiv.org/abs/2310.05654
[2] Bolya, Daniel, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. 2023. “Token Merging: Your ViT But Faster.” arXiv preprint arXiv:2210.09461. https://arxiv.org/abs/2210.09461
[3] Shao, Kele, Keda Tao, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. 2025. “When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios.” arXiv preprint arXiv:2507.20198. https://arxiv.org/abs/2507.20198.
[4] Li, Kaiyuan, Xiaoyue Chen, Chen Gao, Yong Li, and Xinlei Chen. 2025. “Balanced Token Pruning: Accelerating Vision Language Models Beyond Local Optimization.” arXiv preprint arXiv:2505.22038. https://arxiv.org/abs/2505.22038
[5] Liu, Ting, Liangtao Shi, Richang Hong, Yue Hu, Quanjun Yin, and Linfeng Zhang. 2024. “Multi-Stage Vision Token Dropping: Towards Efficient Multimodal Large Language Model.” arXiv preprint arXiv:2411.10803. https://arxiv.org/abs/2411.10803
[6] Li, Yuang, Yu Wu, Jinyu Li, and Shujie Liu. 2023. “Accelerating Transducers through Adjacent Token Merging.” arXiv preprint arXiv:2306.16009. https://arxiv.org/abs/2306.16009
[7] Cao, Qingqing, Bhargavi Paranjape, and Hannaneh Hajishirzi. 2023. “PuMer: Pruning and Merging Tokens for Efficient Vision Language Models.” arXiv preprint arXiv:2305.17530. https://arxiv.org/abs/2305.17530
[8] Shang, Yuzhang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. 2024. “LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models.” arXiv preprint arXiv:2403.15388. https://arxiv.org/abs/2403.15388
[9] Li, Junnan, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. “BLIP-2: Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models.” arXiv preprint arXiv:2301.12597. https://arxiv.org/abs/2301.12597
[10] Zhang, Yuanhan, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2025. “LLaVA-Video: Video Instruction Tuning with Synthetic Data.” arXiv preprint arXiv:2410.02713. https://arxiv.org/abs/2410.02713
[11] Chen, Zhe, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, and et al. 2024. “How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites.” arXiv preprint arXiv:2404.16821. https://arxiv.org/abs/2404.16821
[12] Dai, Wenliang, Nayeon Lee, Boxin Wang, Zhuolin Yang, Zihan Liu, Jon Barker, et al. 2024. “NVLM: Open Frontier-Class Multimodal LLMs.” arXiv preprint arXiv:2409.11402. https://arxiv.org/abs/2409.11402
[13] Cha, J., Kang, W., Mun, J., and Roh, B. 2024. “Honeybee: Locality-Enhanced Projector for Multimodal LLM.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
[14] Li, Yanwei, Chengyao Wang, and Jiaya Jia. 2023. “LLaMA-VID: An Image Is Worth 2 Tokens in Large Language Models.” arXiv preprint arXiv:2311.17043. https://arxiv.org/abs/2311.17043